Recursive Information Markets mockup for Metaculus
Introduction/motivation
There are many contexts in which someone may seek information, and countless mechanisms have been designed for it.
- Customer reviews, for when you want information before making a purchase (similarly: referencing before you hire/rent to/loan to someone)
- Regulatory inspections, for the same purpose.
- Recommender systems, when you want some videos or music or articles or recent hot takes or whatever
- News media, for when you want the day's news
- Community notes, for when you want information before believing a tweet or news article
- Academia, for when you want to discover truths about the world
- Wikipedia, for when you want to learn some well-known facts
- Search engines/AI assistants, for when you want … whatever.
To a market fundamentalist like me, this is simply embarassing. If you want something, the right way to get it should be to buy it! Why can't we have a market for information?
And indeed, nearly all of these mechanisms are clearly broken. Nobody trusts academia. Nobody trusts news media. Recommender systems have created a brain-rotted generation (OK, I think they have done a lot of good too but you know what I mean). Wikipedia is a cliquey government bureaucracy. Reviews are often very ill-informed. All of these institutions are basically our civilizational cope for not having information markets.
So what goes wrong with simple, naive information markets?
- Buyer's inspection paradox – by definition someone selling you information has an information asymmetry advantage against you. If you let the buyer bridge this asymmetry by inspecting the information before buying it, all incentives break down because the buyer cannot "return"/forget the information he has seen.
- Information asymmetry – even if you did somehow have the buyer inspect the information he's purchasing, he might still be subject to information asymmetry just as in any market (though the effects are more pronounced for information, because the value of arbitrary natural-language information usually closely depends on important contextual information or verification). This means the seller is incentivized to optimize for the buyer's superficial judgement (to "fool" the buyer) rather than for the buyer's more informed judgement (extrapolated volition).
- Low cost of duplication – Once you sell it to someone, it is hard to prevent them from redistributing it. Ideally the low marginal cost of production means information should have differential pricing, but the fact that others can also duplicate it makes this hard.
- Transaction costs of tenders – Often buying information involves "tenders and proposals": the buyer requests information, a bunch of sellers produce it, and the buyer selects the best one to buy. If you have the sellers just produce "proposals" then pick one to contract, then the seller will just swindle you (ignoring heuristic things like reputation). If you have the sellers produce everything upfront, then that will require a lot of sellers to go through the laborious process for no reward (and the buyer can now swindle the sellers!). In practice this is why the white-collar economy doesn't run on freelancing but instead has things like employment and career progression.
- Learning is a transaction cost – augmenting your intelligence is a form of information. However, the greatest cost in doing so is often not the price of the information itself, but the transaction cost of learning it.
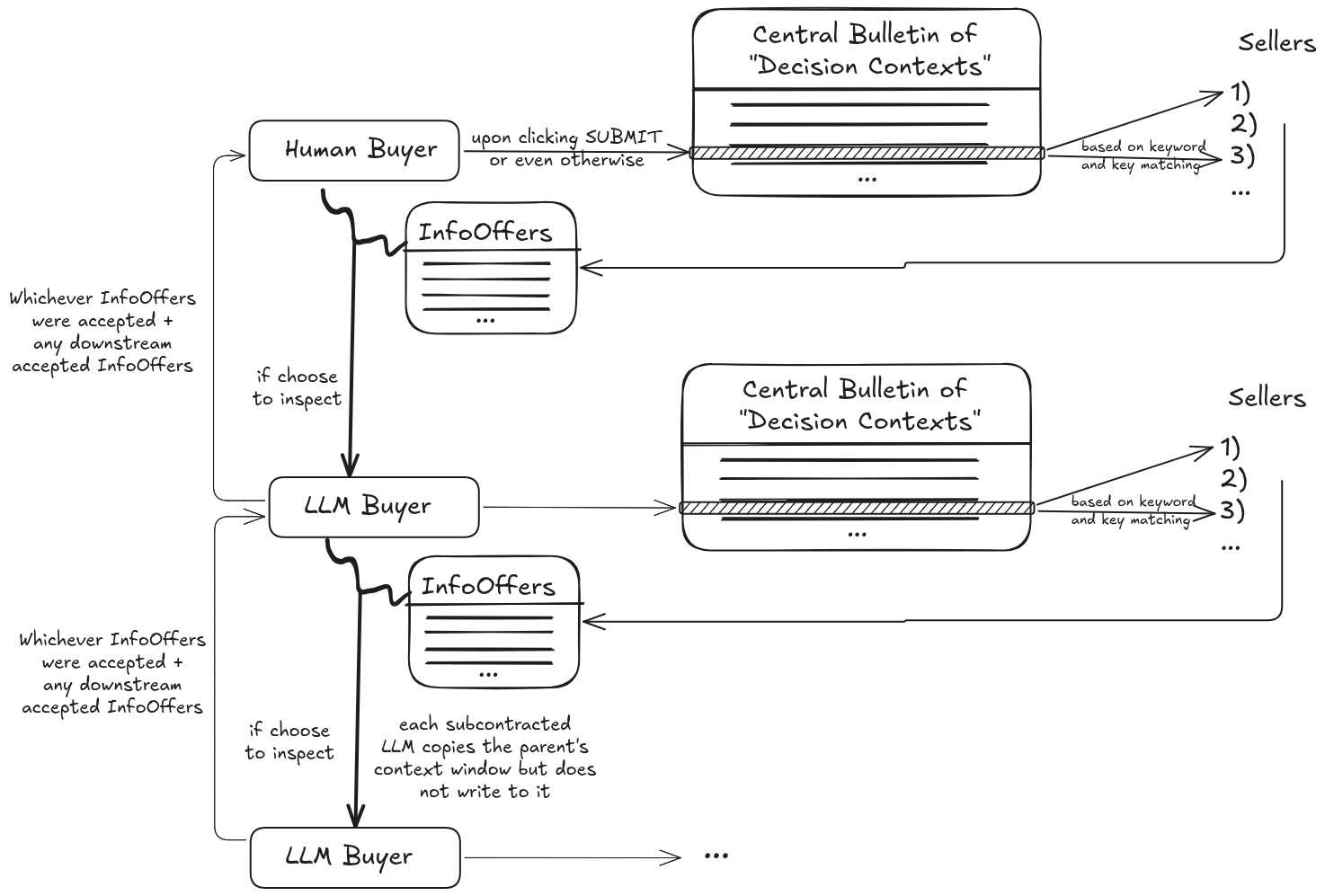
Weiss & Rahaman (2024) propose a solution to the first problem: the Information Bazaar. Instead of humans inspecting the information directly, they should have to subcontract LLM buyers to decide what to buy for them. If the LLM buyers, after inspecting the information, decide not to buy the information, they forget (delete from context window) the information forever.
They did not consider the second problem, that this does not fully eliminate information asymmetry (I am especially interested in this because in an RLHF setting, where the human does inspect the AI's outputs and gives his valuation for it, this is the main source of remaining information asymmetry).
I propose the Recursive Information Bazaar: where not only can human buyers purchase on the Information Bazaar — but the LLM buyers they subcontract can also buy information on the Information Bazaar to help inform their purchase decision during inspection.
The reason for implementing this at Metaculus is two-fold:
- IMO it makes sense for Metaculus (or any prediction market/forecasting platform) to expand into a general-purpose information market, where users can get the best possible answer to any question, not just objective questions with ground truth that will be revealed at some point in future.
- One obvious application for information markets is to inform forecasters. In fact I would say a fundamental limitation of prediction markets/forecasting platforms is that it does not calculate "derived demand": forecasters are not incentivized to e.g. create markets for the questions that would improve their forecasts, because those market probabilities would public. Any market subsidy is a positive externality.
Algorithm sketch and UI
Overview
Decision Contexts
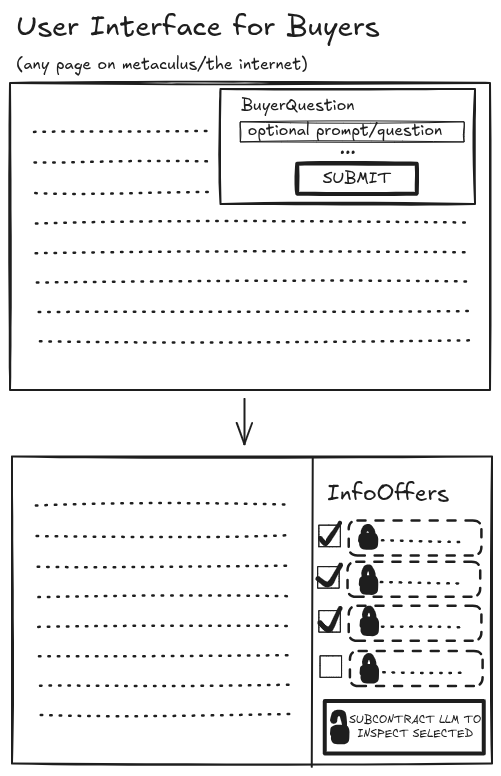
When a user ("Buyer") is viewing a forecasting question, comment or really any page on Metaculus, this "context" is submitted to a Central Bulletin of "Decision contexts".
The Buyer should have a UI to add additional context to help the information sellers help him, and more generally the Decision Context could include arbitrary amounts of information about the user if he so chooses, e.g.
- Custom prompt or query explaining what he wants
- Page info (i.e. which forecasting question he's viewing) – maybe the Buyer UI should include an option "Include Page Info", if the Buyer is asking for info unrelated to the page.
- Multi-page info – if the buyer wants information related to multiple questions
- Maximum budget
- Specific seller IDs, if he only wants info from some sellers (e.g. "explain your forecast")
- Is Submitted? – was the Decision Context manually submitted by the user or was just automatically sent to the bulletin. Sellers would usually ignore the latter sort of context, unless there is something very unexpected to be said about certain questions ("you need to hear this!!")
- Buyer-specific info – e.g. how often do they inspect/purchase info (conditional on Is Submitted)? What is their general expertise? How have they scaffolded their LLM buyer (e.g. maybe they prompted it to say "I love irrelevant ads!" or "only inspect one piece of info")
- Timestamp/age of query – e.g. sellers might want to wait some time before responding to
is_submitted=Falsequeries, in case the Buyer replaces it; or might not want to respond to very old queries.
If the Buyer hits SUBMIT on some page, the new is_submitted=True query should replace the previous is_submitted=False query.
Fetch Seller Info
Seller Info could be static (a fixed piece of info that he sells to relevant queries, like web search) or dynamic (generated based on the query). Sellers might want to fetch queries filtered by:
- keyword matches in the prompt or page info
- Is submitted?
- more generally (keyword matches in) any key
- seller ID match
- Max queries to fetch
Either the Central Bulletin can be public (except for the ones specific to seller ID) and sellers can fetch from it via API, or the Bulletin can be kept private, the sellers can pre-set the keys and keywords they are interested in, and are sent the relevant matches.
The info they give will consist of:
- Private info (the main stuff)
- Optional public info (e.g. metadata, seller identity, short description – though this could also be part of private info)
- Price (can be private or public)
- How long to keep private? Maybe for now: we centrally set a maximum duration, sellers can choose which tournaments their info is related to (and it will become public once those tournaments are over), and if it was dynamically generated in response to the buyer's query and the query was for some forecasting question it can just be related to that tournament.
- Human or bot info-seller?
Inspect InfoOffers
The buyer gets the list of InfoOffers, with private info kept hidden. It selects which offer to inspect, and spins off an LLM Buyer to inspect and purchase them.
The LLM Buyer must now return the list of InfoOffers to buy. But doing so itself entails a new Decision Context!
And so we return to Step 1, and the recursion continues until the LLM Buyer decides not to inspect any received InfoOffers and just returns the InfoOffers to buy. The Decision Context is removed, these InfoOffers are purchased and yielded to the LLM Buyer's principal (either the Human Buyer, or an LLM Buyer at some recursive step) who then continues to make their decision (either selecting another set of InfoOffers to inspect with a new child LLM, or making their decision and yielding to their principal).
A note on Waiting
It is not necessary that the buyer receives all InfoOffers together – human InfoOffers might of course take a very long time, and even some AI InfOffers might take some time. There should be a page where the InfoOffers to a particular query loads (unless the buyer chooses to retire that query), and the user should be notified for new InfoOffers that load.
With that said, the Buyer does face an important decision of "when to inspect", because the LLM inspects all its chosen InfoOffers together (in the same context), for the sake of competition. The Buyer can still inspect the new InfoOffers later, but there will be less competition for it.
(This doesn't incentivize slowness though, because you do increase the chances of someone else giving the important info the longer you take.)
User settings
- Enable Information Market
- Auto-submit on every page load
- LLM scaffolding
- Auto-inspect (based on some heuristic)
Practical matters
How to actually get people to transact information?
Information use cases
Pro-forecasters' reasoning/cruxes, base rates etc.
Domain-specific expertise
Change-my-view
"Local" questions that people of some country/city are more informed on
What sort of questions likely benefit from information markets?
These factors make it LESS likely:
Very hotly-debated topics (well-known geopolitical events, AI timelines)
By "well-known" I mean: anything involving America, China, Russia or Israel. Everything else is quite murky and can benefit from information markets.
Still, questions that depend on highly-numerical matters (e.g. US involvement in Israel-Iran might depend on how many missiles each country has)
Stuff that depends on just one guy's decision
Simple extrapolation questions
These factors make it MORE likely
Lots of previous data to infer base rates from
Domain-specific expertise
Questions that depend on numerical details
"Random facts that might be useful"
Often I find some "high-signal" pieces of information. The sort of thing I'd retweet. I wouldn't know exactly what questions it would be useful for, but I can tell it's something broadly instrumentally useful, and might just post it on the information market for people's use. Often this is the sort of thing you can't get by searching unless you know what you're looking for.
It might be difficult to do this at scale in a Metaculus tournament, but long run I expect this to be quite valuable.
Nudging
nudging forecasters for some good query ideas (and maybe even having an LLM pre-ask them, so they can just click on that query to ask it), such as those in "Information use cases" or stuff an LLM thinks of on the fly.
nudging people to give info on each ForecastingQuestion page "Want to instead give some useful info to other forecasters? You can earn InfoPoints by providing information/reporting that other users will buy"
AI pre-generation of queries
Something that might make sense is to have AI brainstorm a bunch of relevant queries for each forecasting question and suggest it to users. It might even make sense to have it post these queries in advance, with a key marked "Bot pre-populated".
Pre-populate with bots
Sellers
Fact-checking bots
"Giving context on papers" bots
Simple perplexity-type bots
… brainstorm
Buyers
Inspectors (simple reputation-based logic)
Might even make the most sense to do my experiments with LLM bots
Unanswered practical questions
How to do scoring?
What "score" or "money" should we use for the transactions (purchases of information etc.)
Existing Metaculus score
I have been told the people will revolt.
New Score
How to make this scoring rule matter to people?
Maybe introduce it as a general: "Beta features" scoring rule, that is used when testing all "beta features".
Or maybe this isn't a problem, and people will appreciate being scored for Information anyway.
Money
Some people will go into the negatives and so will have to pay to participate.
"What if we set the baseline at zero and distribute the prize?" — this just incentivizes people to make huge transactions between fake accounts so their recepient account gets all of the prize.
Portion of prize money
Differential pricing leads to an obvious arbitrage opportunity: create a burner account to just buy info.
"But isn't that just like people leaking info?" Leaking info on the site can be restricted, and for leaking info off-the-site we can at least threaten to ban accounts. OTOH quite hard to figure out whose burner account something is.
How to run the LLM bots?
We should make them submit the source code and run it server-side.
What is the "experiment"?
Extensions
Interactivity
Information sellers should be able to say "Working on it, expected time: …" This would produce a non-inspectable/free InfoOffer that is replaced as soon as the seller completes their InfoOffer.
More generally we might want InfoOffers to be interactive. The seller might want to ask the buyer some questions to clarify what it wants, or they might negotiate a price. One risk of doing this naively is that since these conversations happen during inspection, they can trivially be exploited to leak a seller's info (to another, maybe dummy, seller). So you would need to make the seller also go into an Amnestic Sandbox during this conversation.
stupid thing I hate
Though, I will note, there will always be one stupid way to leak info: create a large number of dummy sellers, then encode the victim's info (in binary) in your choices of which dummy sellers to buy from.
Other interfaces
It might be worth it to make a browser extension … or just an API that can be called like an LLM, you know? Set all user settings, LLM buyer scaffolding logic, auto-inspection logic, in some .infomarket/ directory and just call the information bazaar like you would call an LLM.