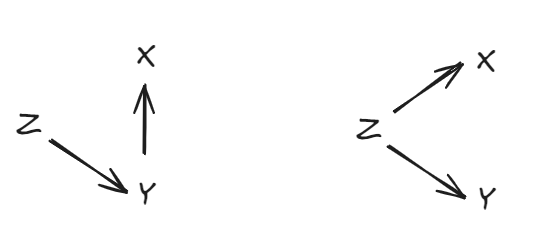transfer / meta learning / generalization / abstractions - the general framework
In the literature I have often seen conflicting definitions for terms like "transfer learning" and "meta learning". E.g. here's a stackexchange question about this.
Here's the general framework encapsulating this idea.
Suppose our universe of interest is given by some joint distribution P(X). This joint distribution is itself not known to us (we want to learn it, after all) but instead we have some distribution ϕpX on the space of possible models. Specific tasks of interest to us like P(X1), P(Y2∣X1) etc. are derived as marginals of the joint distribution, and therefore are "random variables" derived from ϕpX which may be correlated etc.
(Note how this is different from the usual "learning from data" setting in which we have a "prior" P(X) which we condition on observed data. In this usual setting, X is a random vector including random variables for observations X1, X2, … and we can simply calculate the conditionals P(X∣X1=x1,X2=x2).)
One way to think about this is to say there's some other (not included in X) random variable Z such that P(X) depends on Z, i.e. P(X∣Z) is a thing, and is what you know. Then when you "learn" the marginal P(X1), you are also getting information on Z, which gives you information on other distributions like P(X2) or P(Y2∣X1), which are also marginalized on Z.
Meta-learning / generalization
Meta-learning in a general sense refers to learning this meta-distribution ϕpX from data. What this means is we now see ϕpX as a distribution that can be sampled from, not just a belief distribution — i.e. we see Z as a random variable that can be sampled.
In the classic meta-learning example of learning random sinusoids (see e.g.): the ϕpX to be learned assigns high probabilities only to sinusoidal P(Y∣X)s — equivalently Z is a random variable representing the generative model, and P(Y∣Z,X) is known to be straightforward functional application so Y = Z(X).
Example: General transfer learning.
Here, learning P(Y1∣X1) helps you learn P(Y2∣X2).
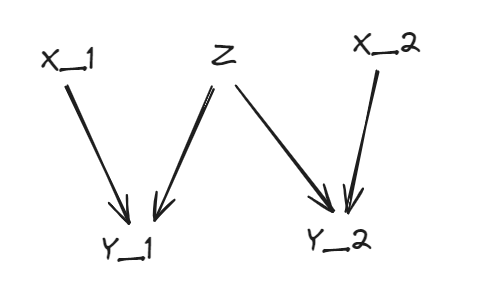
Note that this doesn't mean P(Y1∣X1) and P(Y2∣X2) are the same or similar in any way (this can be taken as the special case where Z is simply exactly a distribution P(Y∣X) and Yi is (i.e. P(Yi∣Xi,Z) is such that:) is just composition Z(Xi)) — as is the case with most standard transfer learning applications such as fine-tuning and style transfer.
Style transfer looks like — θ and θ’ represent two different "styles" (e.g. "formal voice" and "pirate voice") and Z represents exactly some common distribution P(Y∣X,θ) = P(Y’∣X,θ’) so that the functional dependence of Y and Y’ on their inputs X is completely determined by it.
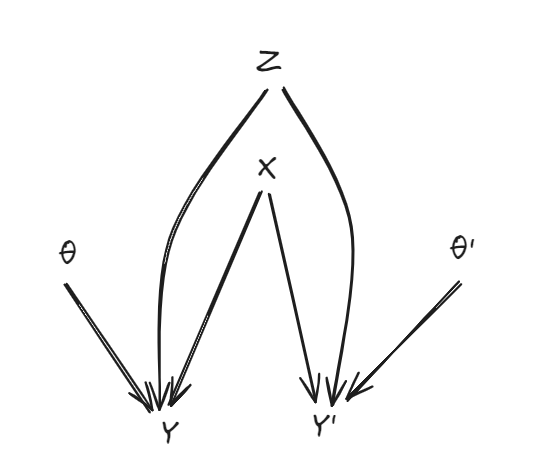
In fine-tuning, the correlation between P(Y∣X) and P(Y’∣X) is governed by a mediating variable — a latent.
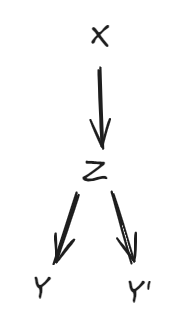
Example: Semi-supervised learning.
Semi-supervised learning is possible when there P(X) and P(Y∣X) are correlated as random variables when sampled from ϕpX.
Equivalently, if there is a random variable Z such that P(X) and P(Y∣X) both depend on it, i.e. $X\corr Z$ and $Y\corr Z\mid X$ (where $\corr$ indicates mutual information and $a\corr b\mid c$ indicates conditional mutual information).
I've written about this with more exposition here, but this is only possible if X and Y have a common cause Z or if Y causes X (in which case you could simply let Z be Y). Semi-supervised learning is not possible when the only causal relationship between X and Y is X → Y — this is known as the principle of independent causal mechanisms.